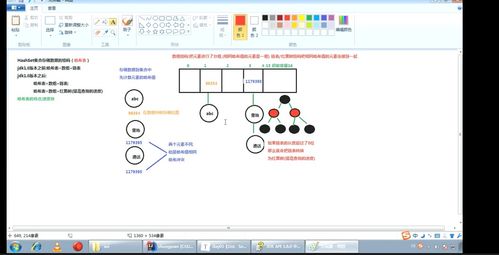
HashSet是Java集合框架中基于哈希表實現的一種數據結構,它主要用于存儲不重復的元素集合。其內部實現依賴于HashMap,通過將元素作為HashMap的鍵(Key)來保證唯一性,而值(Value)則統一為一個靜態的常量對象。這種設計使得HashSet在添加、刪除和查找操作上具有接近常數時間復雜度(O(1))的高效性能,尤其適合處理大量數據且需要快速去重的場景。
一、HashSet的存儲結構特點
HashSet的核心存儲結構是哈希表(Hash Table),它通過哈希函數將元素映射到表中的特定位置(桶)。每個桶可以存儲一個或多個元素(在發生哈希沖突時,Java 8之后采用鏈表或紅黑樹處理)。HashSet的主要特性包括:
- 元素唯一性:基于哈希碼和equals方法判斷重復,確保集合中無重復元素。
- 無序性:元素存儲順序不固定,取決于哈希函數和內部擴容機制。
- 高效操作:添加、刪除和查找的平均時間復雜度為O(1),最壞情況(如所有元素哈希沖突)下可能退化到O(n)。
- 允許null元素:HashSet可以存儲一個null值,但多次添加null不會增加元素數量。
二、HashSet在數據處理中的應用
在數據處理服務中,HashSet常用于以下場景:
- 數據去重:快速過濾重復記錄,如日志清洗或用戶ID去重。
- 成員檢測:高效判斷某個元素是否存在于集合中,如黑名單檢查或緩存查詢。
- 集合運算:通過union(并集)、intersection(交集)等操作處理數據集,例如合并多個數據源并去除重復項。
三、HashSet在存儲支持服務中的角色
作為存儲支持服務的一部分,HashSet通常作為內存數據結構,為上層應用提供臨時或高速的數據管理能力:
- 緩存層實現:結合LRU(最近最少使用)策略,用HashSet存儲鍵值以實現快速查找,減少數據庫訪問壓力。
- 索引輔助:在分布式存儲系統中,HashSet可用于維護部分索引或元數據,加速查詢響應。
- 實時數據處理:在流處理框架(如Apache Flink)中,HashSet可暫存狀態數據,支持窗口計算或事件去重。
四、注意事項與優化建議
盡管HashSet性能優越,但在實際應用中需注意:
- 哈希函數設計:自定義對象需重寫hashCode和equals方法,以保證哈希分布均勻和正確性。
- 內存消耗:哈希表可能因負載因子過高導致擴容,增加內存開銷,需合理設置初始容量和負載因子。
- 線程安全:HashSet非線程安全,多線程環境下應使用ConcurrentHashMap或Collections.synchronizedSet包裝。
- 數據持久化:HashSet為內存結構,需結合數據庫或文件系統實現數據持久化,避免服務重啟導致數據丟失。
HashSet憑借其高效的哈希存儲機制,在數據處理和存儲支持服務中扮演著重要角色。通過合理利用其特性,可以顯著提升系統的性能和可擴展性,尤其是在需要快速去重和查詢的場景中。開發者也需根據具體需求權衡其內存使用和線程安全性,以確保服務的穩定與高效運行。