1. 系統概述與核心需求
一個優秀的短鏈接服務(如TinyURL、Bitly)不僅需要將長URL映射為短字符串,還必須具備高可用、低延遲、可擴展和安全等特性。核心功能包括:短鏈接生成、重定向、訪問統計和過期管理。設計時應重點考慮數據處理與存儲支持服務,確保系統穩定高效。
2. 數據處理流程設計
2.1 短鏈接生成算法
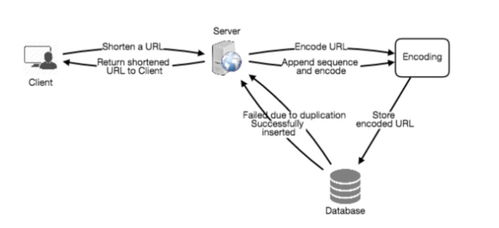
- 哈希算法(如MD5、SHA-1):對原始URL進行哈希,取前N位作為短碼。需解決哈希沖突(例如通過追加隨機鹽重試)。
- 自增ID編碼:使用分布式ID生成器(如雪花算法)產生唯一ID,再通過Base62編碼轉換為短字符串。優點是無需沖突處理,且可按序存儲。
- 預生成短碼池:提前批量生成隨機短碼存入數據庫,使用時直接分配,避免實時生成壓力。
2.2 重定向與緩存策略
- 301 vs 302重定向:
- 301永久重定向利于SEO,但可能減少統計次數。
- 302臨時重定向便于實時統計訪問數據。
- 多級緩存優化:
- 熱點短鏈接存入Redis/Memcached,設置TTL(如24小時),加速查詢。
- 使用CDN緩存高頻訪問鏈接,減少回源請求。
2.3 數據統計與異步處理
- 訪問日志通過消息隊列(如Kafka)異步寫入,避免阻塞重定向主流程。
- 采用OLAP數據庫(如ClickHouse)存儲統計信息,支持時間、地域、設備等多維度分析。
3. 存儲架構設計
3.1 數據庫選型與分片策略
- 主存儲:關系型數據庫(如MySQL/PostgreSQL)存儲核心映射關系,表結構包括:短碼(主鍵)、原始URL、創建時間、過期時間、創建者等。
- 分片方案:
- 按短碼哈希值分片,避免熱點數據傾斜。
- 按用戶ID分片,便于用戶數據隔離與管理。
- 備份與讀寫分離:主從復制保障高可用,讀操作分流到從庫。
3.2 大規模數據存儲優化
- 冷熱數據分離:
- 熱數據(近期活躍鏈接)存于SSD數據庫實例。
- 冷數據(過期或低頻訪問)歸檔至對象存儲(如S3)或時序數據庫。
- 數據壓縮:對原始URL使用字典壓縮(如Zstandard),減少存儲空間。
3.3 容災與一致性保障
- 多地域部署:通過DNS負載均衡將用戶路由至最近數據中心,數據庫采用跨地域同步(如MySQL Group Replication)。
- 最終一致性模型:緩存與數據庫間允許短暫不一致,通過監聽binlog或定期刷新緩存同步數據。
4. 安全與擴展性考量
- 防止濫用:
- 限制同一IP/用戶的生成頻率。
- 對惡意URL(如釣魚網站)進行實時檢測與過濾。
- 擴展性設計:
- 無狀態服務層便于水平擴展。
- 存儲層可通過分片與代理中間件(如Vitess)彈性擴容。
5. 監控與運維建議
- 關鍵指標監控:QPS、重定向延遲、緩存命中率、存儲可用空間。
- 自動化運維:短鏈接過期清理腳本、存儲分片平衡工具。
設計短鏈接服務的核心在于平衡性能、成本與可靠性。通過合理的數據處理流程、分層存儲架構及容災機制,可構建一個支撐億級請求的高可用系統。未來可結合AI預測熱點鏈接,進一步優化資源分配。