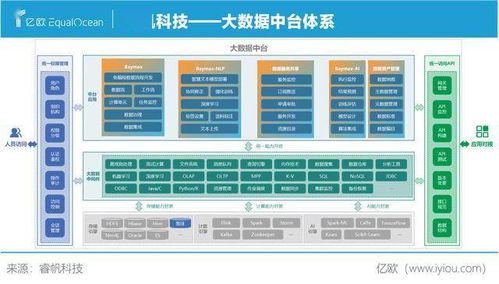
在當今信息爆炸的時代,大數據已不再是一個陌生的概念,而是推動各行各業數字化轉型的重要引擎。無論是企業決策、科學研究,還是社會治理,大數據的價值日益凸顯。大數據的價值并非自動生成,而是依賴于高效、可靠的數據處理與存儲支持服務。本文將深入探討大數據背景下數據處理與存儲支持服務的內涵、關鍵技術與應用實踐。
一、大數據的內涵與挑戰
大數據通常被概括為“5V”特征:Volume(大量)、Velocity(高速)、Variety(多樣)、Value(低價值密度)、Veracity(真實性)。這些特征決定了傳統數據處理與存儲方式難以應對,從而催生了專門的技術與服務需求。例如,每天產生的社交媒體數據、物聯網設備數據等,不僅數量龐大,而且需要實時處理,同時數據格式各異(如文本、圖像、視頻),從中提取有價值信息猶如大海撈針。
二、數據處理支持服務:從原始數據到洞察力
數據處理是挖掘大數據價值的關鍵步驟,它包括數據采集、清洗、轉換、分析和可視化等環節。隨著技術發展,數據處理支持服務已形成一套完整的生態系統:
- 數據采集與集成:通過API、爬蟲、傳感器等方式收集多源數據,并利用ETL(提取、轉換、加載)工具進行整合。例如,企業可使用Apache NiFi或Kafka實現實時數據流處理。
- 數據清洗與預處理:大數據中常包含噪聲、缺失值或不一致信息,需借助自動化工具(如Python的Pandas庫或專業數據質量平臺)進行清洗,確保數據質量。
- 數據分析與挖掘:利用機器學習、統計分析等技術,從數據中發現模式、趨勢和關聯。云計算平臺如AWS、阿里云提供了托管的數據分析服務(如Amazon EMR、MaxCompute),降低了技術門檻。
- 數據可視化與報告:通過Tableau、Power BI等工具,將復雜數據轉化為直觀圖表,助力決策者快速理解信息。
這些服務不僅提升了數據處理效率,還通過自動化減少了人為錯誤,使組織能夠更專注于業務洞察而非技術細節。
三、數據存儲支持服務:構建可靠的數據基礎
數據存儲是大數據的基石,面對海量數據,傳統數據庫已力不從心。現代數據存儲支持服務呈現出多樣化、可擴展的特點:
- 分布式存儲系統:如Hadoop HDFS、Google Cloud Storage,通過將數據分散在多個節點,實現了高容量和高可用性。它們適用于存儲非結構化或半結構化數據,支持批量處理。
- NoSQL數據庫:包括文檔型(MongoDB)、鍵值型(Redis)、列存儲(Cassandra)等,靈活應對多樣數據格式,適用于實時應用場景。
- 云存儲服務:公有云提供商(如微軟Azure、騰訊云)提供彈性、按需付費的存儲解決方案,企業無需自建數據中心,即可享受高可靠性和全球訪問能力。
- 數據湖與數據倉庫:數據湖(如AWS S3)存儲原始數據,支持多種分析;數據倉庫(如Snowflake、Google BigQuery)則優化了查詢性能,用于結構化數據分析。結合兩者,企業能構建統一的數據管理平臺。
這些存儲服務不僅保障了數據安全與合規性(如通過加密和備份策略),還通過自動化運維降低了成本。
四、實踐應用:驅動行業創新
數據處理與存儲支持服務已在諸多領域落地生根:
- 金融行業:銀行利用實時數據處理檢測欺詐交易,同時借助分布式存儲管理客戶歷史數據,提升風險控制能力。
- 醫療健康:醫院通過大數據分析患者記錄,優化治療方案;云存儲支持基因測序數據的長期保存與共享。
- 智能制造:物聯網設備產生大量傳感器數據,邊緣計算與云端存儲結合,實現預測性維護和生產優化。
- 智慧城市:交通管理部門處理實時監控數據,存儲于數據湖中,用于流量分析和城市規劃。
這些案例表明,高效的數據處理與存儲服務是釋放大數據潛能的前提。企業或機構在選擇服務時,需綜合考慮數據規模、實時性需求、預算及技術團隊能力。
五、未來展望:智能化與可持續發展
隨著人工智能和邊緣計算的發展,數據處理與存儲服務正邁向更智能化的階段。例如,自動化機器學習(AutoML)將簡化數據分析流程,而量子存儲技術有望突破容量瓶頸。綠色計算和節能存儲方案成為關注焦點,推動大數據產業可持續發展。
大數據時代的數據處理與存儲支持服務不僅是技術工具,更是組織競爭力的核心。通過擁抱這些服務,我們能夠將海量數據轉化為切實的洞察與價值,開創更加智能、高效的未來。